publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2026
- ICLR 2026
 Discrete Adjoint MatchingOswin So, Brian Karrer, Chuchu Fan, Ricky T. Q. Chen, and Guan-Horng LiuIn The Fourteenth International Conference on Learning Representations (ICLR), 2026
Discrete Adjoint MatchingOswin So, Brian Karrer, Chuchu Fan, Ricky T. Q. Chen, and Guan-Horng LiuIn The Fourteenth International Conference on Learning Representations (ICLR), 2026Computation methods for solving entropy-regularized reward optimization—a class of problems widely used for fine-tuning generative models—have advanced rapidly. Among those, Adjoint Matching (AM, Domingo-Enrich et al., 2025) has proven highly effective in continuous state spaces with differentiable rewards. Transferring these practical successes to discrete generative modeling, however, remains particularly challenging and largely unexplored, mainly due to the drastic shift in generative model classes to discrete state spaces, which are nowhere differentiable. In this work, we propose Discrete Adjoint Matching (DAM)—a discrete variant of AM for fine-tuning discrete generative models characterized by Continuous-Time Markov Chains, such as diffusion-based large language models. The core of DAM is the introduction of discrete adjoint—an estimator of the optimal solution to the original problem but formulated on discrete domains—from which standard matching frameworks can be applied. This is derived via a purely statistical standpoint, in contrast to the control-theoretic viewpoint in AM, thereby opening up new algorithmic opportunities for general adjoint-based estimators. We showcase DAM’s effectiveness on synthetic and mathematical reasoning tasks.
- ICLR 2026
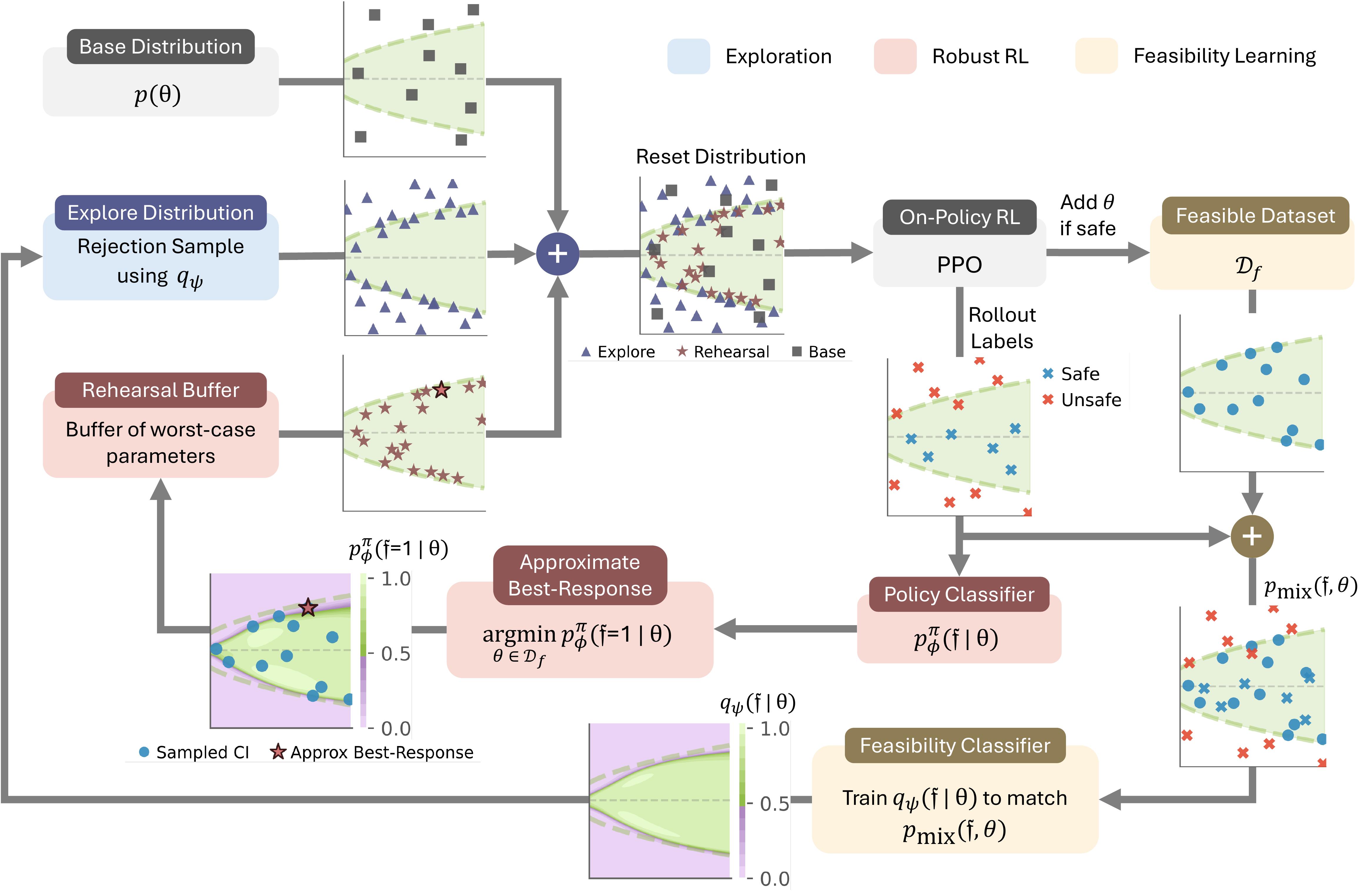 Solving Parameter-Robust Avoid Problems with Unknown Feasibility using Reinforcement LearningOswin So*, Eric Yang Yu*, Songyuan Zhang, Matthew Cleaveland, Mitchell Black, and Chuchu FanIn The Fourteenth International Conference on Learning Representations (ICLR), 2026
Solving Parameter-Robust Avoid Problems with Unknown Feasibility using Reinforcement LearningOswin So*, Eric Yang Yu*, Songyuan Zhang, Matthew Cleaveland, Mitchell Black, and Chuchu FanIn The Fourteenth International Conference on Learning Representations (ICLR), 2026Recent advances in deep reinforcement learning (RL) have achieved strong results on high-dimensional control tasks, but applying RL to reachability problems raises a fundamental mismatch: reachability seeks to maximize the set of states from which a system remains safe indefinitely, while RL optimizes expected returns over a user-specified distribution. This mismatch can result in policies that perform poorly on low-probability states that are still within the safe set. A natural alternative is to frame the problem as a robust optimization over a set of initial conditions that specify the initial state, dynamics and safe set, but whether this problem has a solution depends on the feasibility of the specified set, which is unknown a priori. We propose Feasibility-Guided Exploration (FGE), a method that simultaneously identifies a subset of feasible initial conditions under which a safe policy exists, and learns a policy to solve the reachability problem over this set of initial conditions. Empirical results demonstrate that FGE learns policies with over 50% more coverage than the best existing method for challenging initial conditions across tasks in the MuJoCo simulator and the Kinetix simulator with pixel observations.
- ICLR 2026
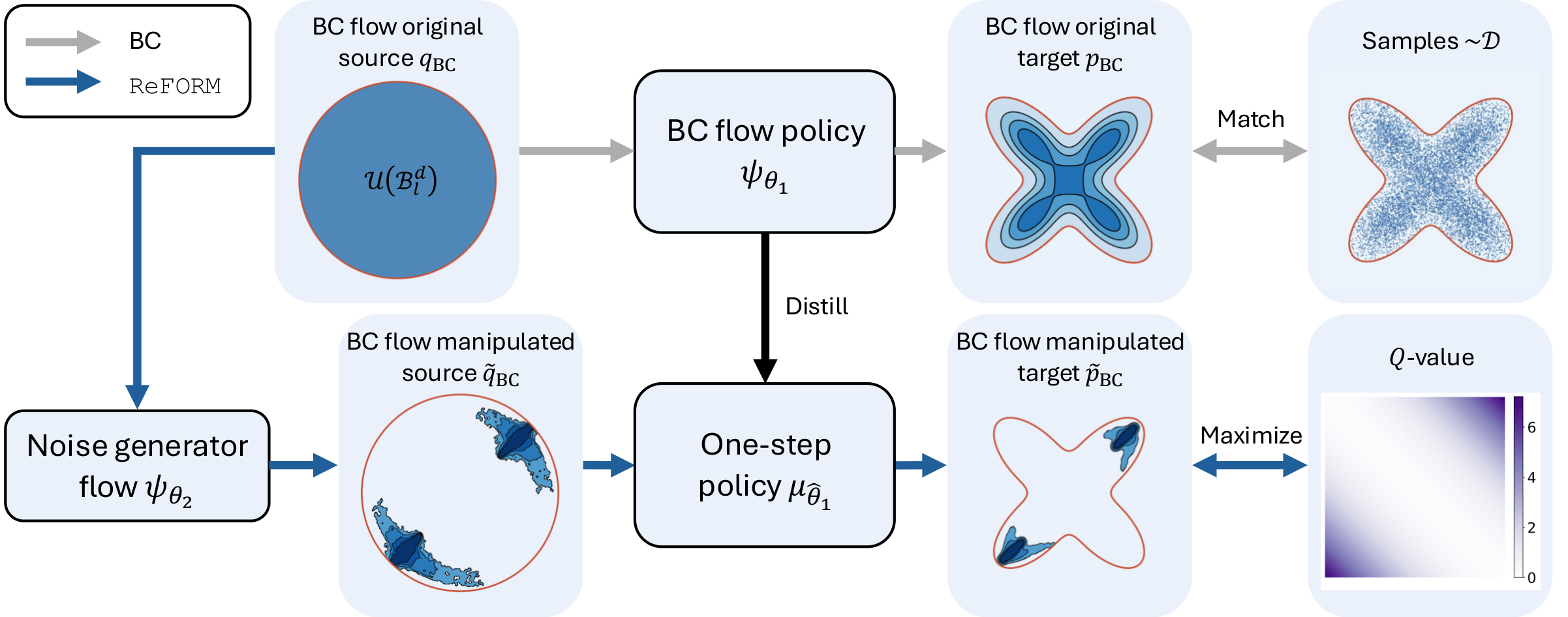 ReFORM: Reflected Flows for On-support Offline RL via Noise ManipulationSongyuan Zhang, Oswin So, H. M. Sabbir Ahmad, Eric Yang Yu, Matthew Cleaveland, Mitchell Black, and Chuchu FanIn The Fourteenth International Conference on Learning Representations (ICLR), 2026
ReFORM: Reflected Flows for On-support Offline RL via Noise ManipulationSongyuan Zhang, Oswin So, H. M. Sabbir Ahmad, Eric Yang Yu, Matthew Cleaveland, Mitchell Black, and Chuchu FanIn The Fourteenth International Conference on Learning Representations (ICLR), 2026Offline reinforcement learning (RL) aims to learn the optimal policy from a fixed behavior policy dataset without additional environment interaction. One com- mon challenge that arises in this setting is the out-of-distribution (OOD) error, which occurs when the policy leaves the training distribution. Prior methods pe- nalize a statistical distance term to keep the policy close to the behavior policy, but this constrains policy improvement and may not completely prevent OOD actions. Another challenge is that the optimal policy distribution can be multimodal and difficult to represent. Recent works apply diffusion or flow policies to address this problem, but it is unclear how to avoid OOD errors while retaining policy expres- siveness. We propose ReFORM, an offline RL method based on flow policies that enforces the less restrictive support constraint by construction. ReFORM learns a BC flow policy with a bounded source distribution to capture the support of the action distribution, then optimizes a reflected flow that generates bounded noise for the BC flow while keeping the support, to maximize the performance. Across 40 challenging tasks from the OGBench benchmark with datasets of varying qual- ity and using a constant set of hyperparameters for all tasks, ReFORM dominates all baselines with hand-tuned hyperparameters on the performance profile curves.



2025
- Nat. Commun.
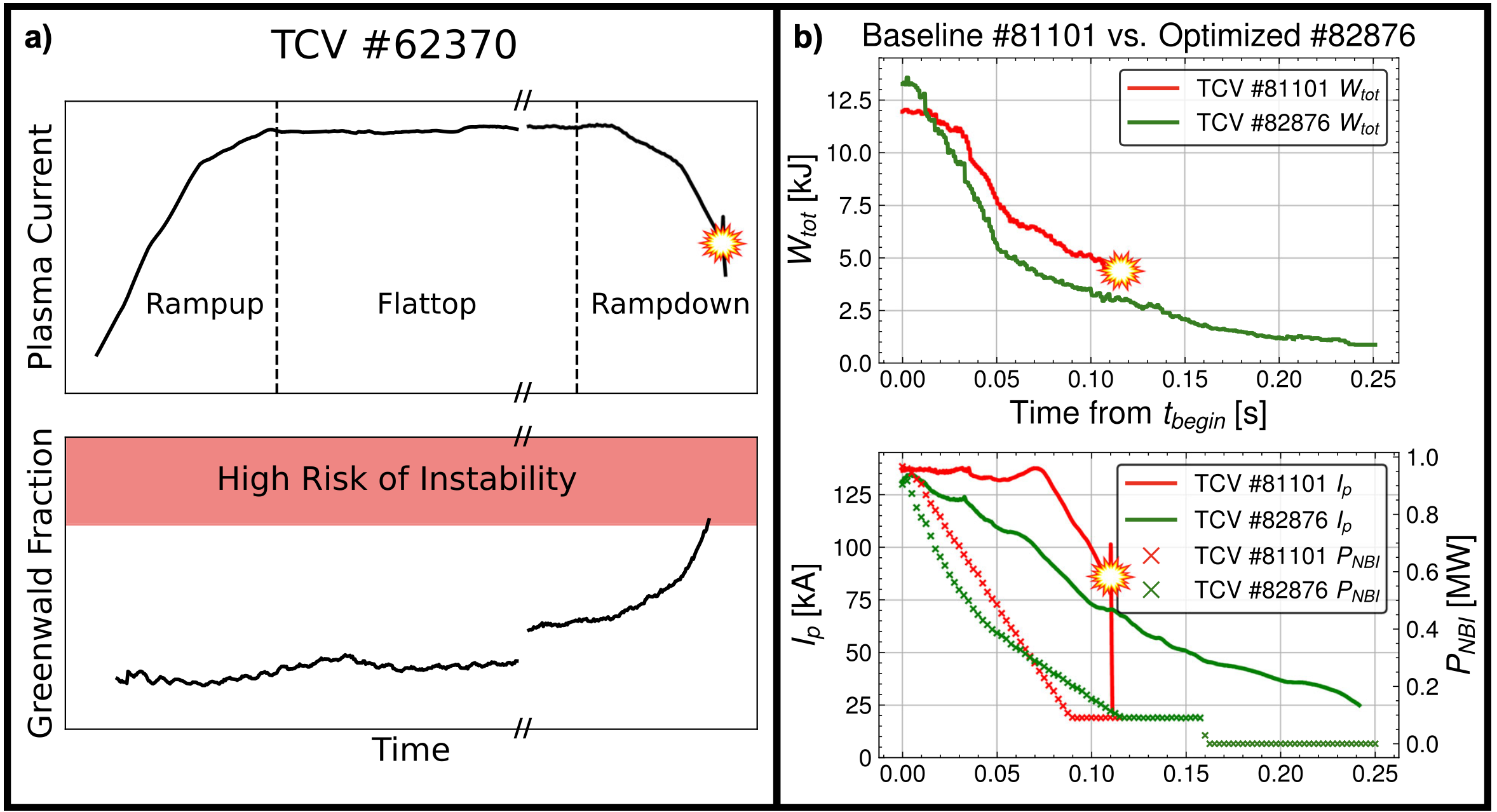 Learning plasma dynamics and robust rampdown trajectories with predict-first experiments at TCVAllen M Wang, Alessandro Pau, Cristina Rea, Oswin So, Charles Dawson, Olivier Sauter, Mark D Boyer, Anna Vu, Cristian Galperti, Chuchu Fan, and othersNature Communications, 2025
Learning plasma dynamics and robust rampdown trajectories with predict-first experiments at TCVAllen M Wang, Alessandro Pau, Cristina Rea, Oswin So, Charles Dawson, Olivier Sauter, Mark D Boyer, Anna Vu, Cristian Galperti, Chuchu Fan, and othersNature Communications, 2025The rampdown phase of a tokamak pulse is difficult to simulate and often exacerbates multiple plasma instabilities. To reduce the risk of disrupting operations, we leverage advances in Scientific Machine Learning (SciML) to combine physics with data-driven models, developing a neural state-space model (NSSM) that predicts plasma dynamics during Tokamak à Configuration Variable (TCV) rampdowns. The NSSM efficiently learns dynamics from a modest dataset of 311 pulses with only five pulses in a reactor-relevant high-performance regime. The NSSM is parallelized across uncertainties, and reinforcement learning (RL) is applied to design trajectories that avoid instability limits. High-performance experiments at TCV show statistically significant improvements in relevant metrics. A predict-first experiment, increasing plasma current by 20% from baseline, demonstrates the NSSM’s ability to make small extrapolations. The developed approach paves the way for designing tokamak controls with robustness to considerable uncertainty and demonstrates the relevance of SciML for fusion experiments.
- RSS 2025
 Solving Multi-Agent Safe Optimal Control with Distributed Epigraph Form MARLSongyuan Zhang*, Oswin So*, Mitchell Black, Zachary Serlin, and Chuchu FanIn Robotics: Science and Systems (RSS), 2025[Outstanding Student Paper Award, 0.6%]
Solving Multi-Agent Safe Optimal Control with Distributed Epigraph Form MARLSongyuan Zhang*, Oswin So*, Mitchell Black, Zachary Serlin, and Chuchu FanIn Robotics: Science and Systems (RSS), 2025[Outstanding Student Paper Award, 0.6%]Outstanding Student Paper Award, 0.6%
Tasks for multi-robot systems often require the robots to collaborate and complete a team goal while maintaining safety. This problem is usually formalized as a Constrained Markov decision process (CMDP), which targets minimizing a global cost and bringing the mean of constraint violation below a user-defined threshold. Inspired by real-world robotic applications, we define safety as zero constraint violation. While many safe multi-agent reinforcement learning (MARL) algorithms have been proposed to solve CMDPs, these algorithms suffer from unstable training in this setting. To tackle this, we use the epigraph form for constrained optimization to improve training stability and prove that the centralized epigraph form problem can be solved in a distributed fashion by each agent. This results in a novel centralized training distributed execution MARL algorithm which we name Def-MARL. Simulation experiments on 8 different tasks across 2 different simulators show that Def-MARL achieves the best overall performance, satisfies safety constraints, and maintains stable training. Real-world hardware experiments on Crazyflie quadcopters demonstrate the ability of Def-MARL to safely coordinate agents to complete complex collaborative tasks compared to other methods.
- RSS 2025
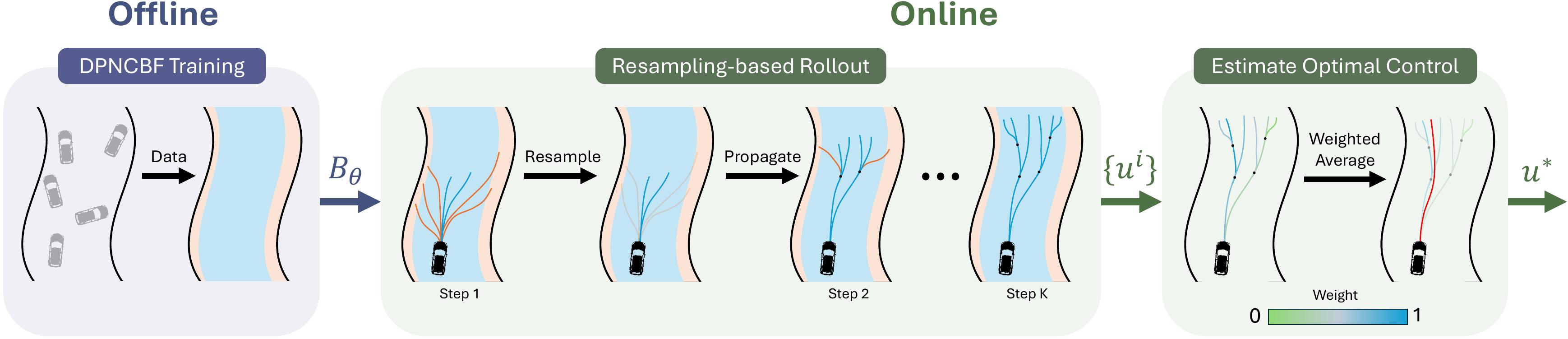 Safe Beyond the Horizon: Efficient Sampling-based MPC with Neural Control Barrier FunctionsYin Ji*, Oswin So*, Eric Yu, Chuchu Fan, and Panagiotis TsiotrasIn Robotics: Science and Systems (RSS), 2025
Safe Beyond the Horizon: Efficient Sampling-based MPC with Neural Control Barrier FunctionsYin Ji*, Oswin So*, Eric Yu, Chuchu Fan, and Panagiotis TsiotrasIn Robotics: Science and Systems (RSS), 2025A common problem when using model predictive control (MPC) in practice is the satisfaction of safety beyond the prediction horizon. While theoretical works have shown that safety can be guaranteed by enforcing a suitable terminal set constraint or a sufficiently long prediction horizon, these techniques are difficult to apply and thus rarely used by practitioners, especially in the case of general nonlinear dynamics. To solve this, we make a tradeoff between exact recursive feasibility, computational tractability, and applicability to black-box dynamics by learning an approximate discrete-time control barrier function and incorporating it into variational inference MPC (VIMPC), a sampling-based MPC paradigm. To handle the resulting state constraints, we further propose a new sampling strategy that greatly reduces the variance of the estimated optimal control, improving the sample efficiency and enabling real-time planning on CPU. The resulting Neural Shield-VIMPC (NS-VIMPC) controller yields substantial safety improvements compared to existing sampling-based MPC controllers, even under badly designed cost functions. We validate our approach in both simulation and real-world hardware experiments.
- AutomaticaComment(s) on “Control barrier functions for stochastic systems” [Automatica 130 (2021) 109688]Oswin So and Chuchu FanAutomatica, 2025
It is shown that Theorem 3 of Clark (2021) is flawed. The proof of Theorem 2 in Clark (2021) relies on the same proof technique and is thus also flawed.
- ICLR 2025
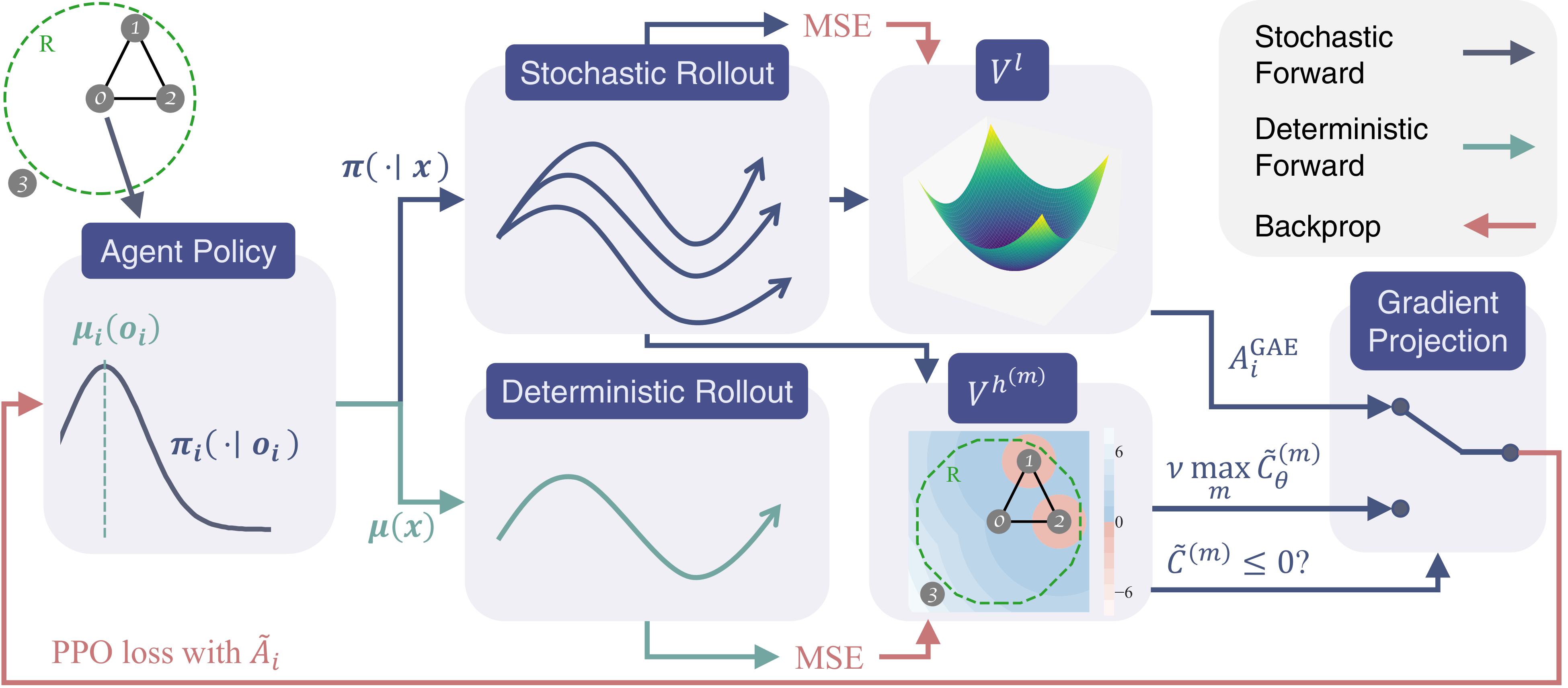 Discrete GCBF Proximal Policy Optimization for Multi-agent Safe Optimal ControlSongyuan Zhang*, Oswin So*, Mitchell Black, and Chuchu FanIn The Thirteenth International Conference on Learning Representations (ICLR), 2025
Discrete GCBF Proximal Policy Optimization for Multi-agent Safe Optimal ControlSongyuan Zhang*, Oswin So*, Mitchell Black, and Chuchu FanIn The Thirteenth International Conference on Learning Representations (ICLR), 2025Control policies that can achieve high task performance and satisfy safety contraints are desirable for any system, including multi-agent systems (MAS). One promising technique for ensuring the safety of MAS is distributed control barrier functions (CBF). However, it is difficult to design distributed CBF-based policies for MAS that can tackle unknown discrete-time dynamics, partial observability, changing neighborhoods, and input constraints, especially when a distributed high-performance nominal policy that can achieve the task is unavailable. To tackle these challenges, we propose DGPPO, a new framework that simultaneously learns both a discrete graph CBF which handles neighborhood changes and input constraints, and a distributed high-performance safe policy for MAS with unknown discrete-time dynamics. We empirically validate our claims on a suite of multi-agent tasks spanning three different simulation engines. The results suggest that, compared with existing methods, our DGPPO framework obtains policies that achieve high task performance (matching baselines that ignore the safety constraints), and high safety rates (matching the most conservative baselines), with a constant set of hyperparameters across all environments.




2024
- T-RO
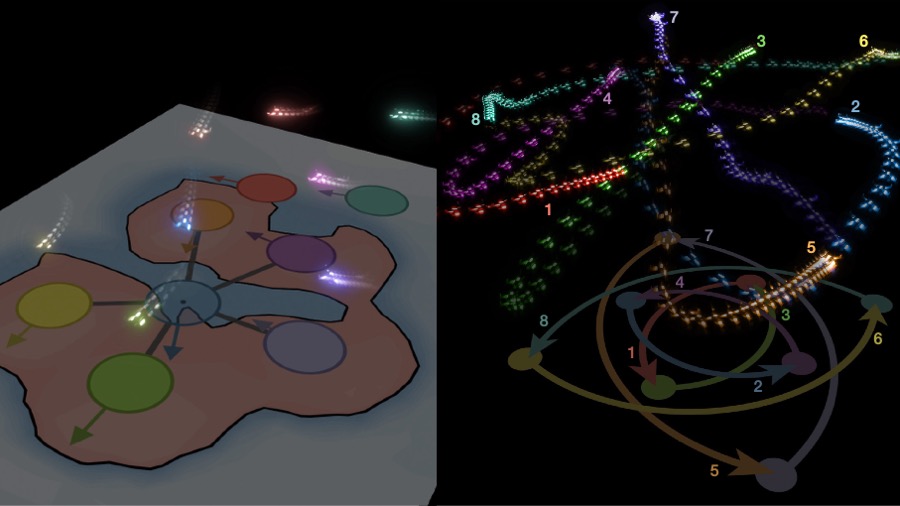 GCBF+: A neural graph control barrier function framework for distributed safe multi-agent controlSongyuan Zhang*, Oswin So*, Kunal Garg, and Chuchu FanIEEE Transactions on Robotics (T-RO), 2024
GCBF+: A neural graph control barrier function framework for distributed safe multi-agent controlSongyuan Zhang*, Oswin So*, Kunal Garg, and Chuchu FanIEEE Transactions on Robotics (T-RO), 2024Distributed, scalable, and safe control of large-scale multi-agent systems (MAS) is a challenging problem. In this paper, we design a distributed framework for safe multi-agent control in large-scale environments with obstacles, where a large number of agents are required to maintain safety using only local information and reach their goal locations. We introduce a new class of certificates, termed graph control barrier function (GCBF), which are based on the well-established control barrier function (CBF) theory for safety guarantees and utilize a graph structure for scalable and generalizable distributed control of MAS. We develop a novel theoretical framework to prove the safety of an arbitrary-sized MAS with a single GCBF. We propose a new training framework GCBF+ that uses graph neural networks (GNNs) to parameterize a candidate GCBF and a distributed control policy. The proposed framework is distributed and is capable of directly taking point clouds from LiDAR, instead of actual state information, for real-world robotic applications. We illustrate the efficacy of the proposed method through various hardware experiments on a swarm of drones with objectives ranging from exchanging positions to docking on a moving target without collision. Additionally, we perform extensive numerical experiments, where the number and density of agents, as well as the number of obstacles, increase. Empirical results show that in complex environments with nonlinear agents (e.g., Crazyflie drones) GCBF+ outperforms the handcrafted CBF-based method with the best performance by up to 20% for relatively small-scale MAS for up to 256 agents, and leading reinforcement learning (RL) methods by up to 40% for MAS with 1024 agents. Furthermore, the proposed method does not compromise on the performance, in terms of goal reaching, for achieving high safety rates, which is a common trade-off in RL-based methods.
- NeurIPS 2024
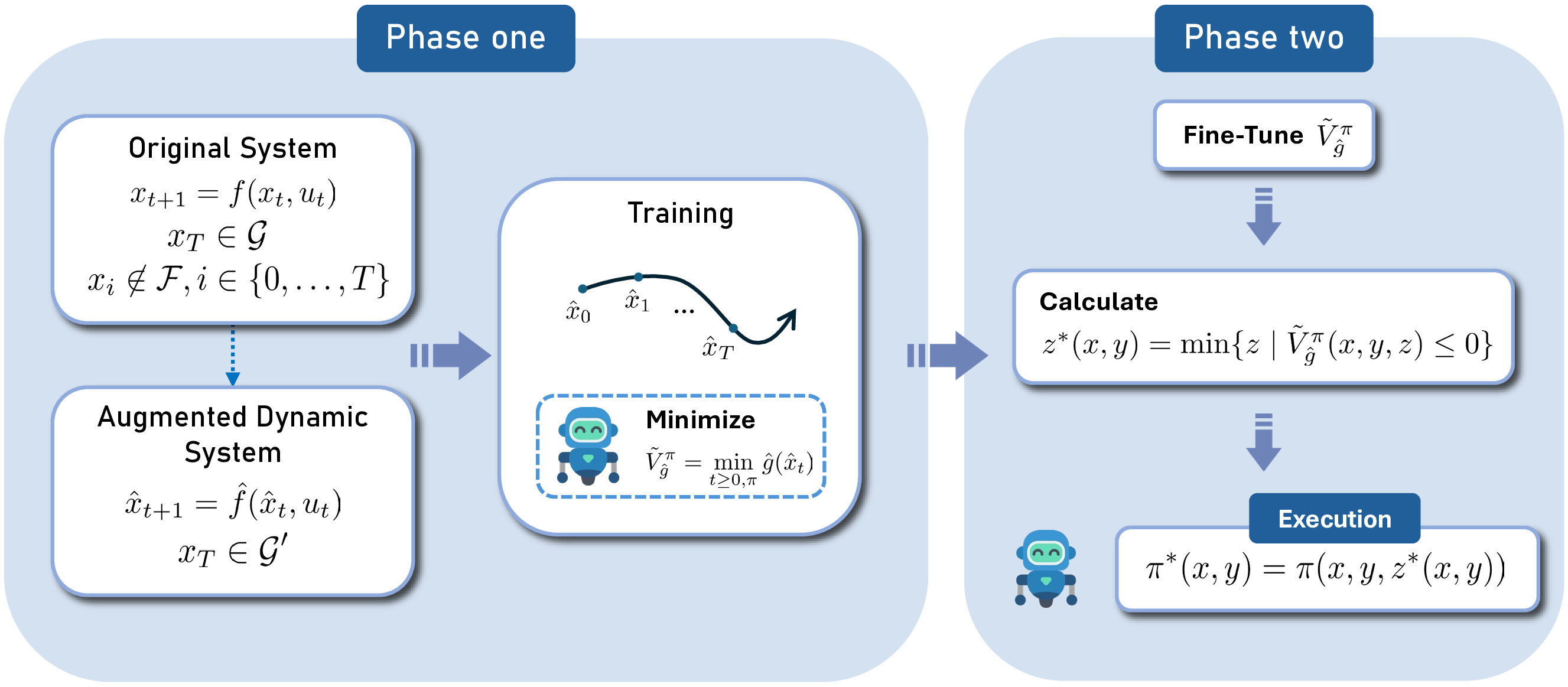 Solving Minimum-Cost Reach Avoid using Reinforcement LearningOswin So*, Cheng Ge*, and Chuchu FanIn Thirty-Eighth Conference on Neural Information Processing Systems (NeurIPS), 2024
Solving Minimum-Cost Reach Avoid using Reinforcement LearningOswin So*, Cheng Ge*, and Chuchu FanIn Thirty-Eighth Conference on Neural Information Processing Systems (NeurIPS), 2024Current reinforcement-learning methods are unable to directly learn policies that solve the minimum cost reach-avoid problem to minimize cumulative costs subject to the constraints of reaching the goal and avoiding unsafe states, as the structure of this new optimization problem is incompatible with current methods. Instead, a surrogate problem is solved where all objectives are combined with a weighted sum. However, this surrogate objective results in suboptimal policies that do not directly minimize the cumulative cost. In this work, we propose RC-PPO, a reinforcement-learning-based method for solving the minimum-cost reach-avoid problem by using connections to Hamilton-Jacobi reachability. Empirical results demonstrate that RC-PPO learns policies with comparable goal-reaching rates to while achieving up to 57% lower cumulative costs compared to existing methods on a suite of minimum-cost reach-avoid benchmarks on the Mujoco simulator.
- ARCLearning safe control for multi-robot systems: Methods, verification, and open challengesKunal Garg, Songyuan Zhang, Oswin So, Charles Dawson, and Chuchu FanAnnual Reviews in Control, 2024
In this survey, we review the recent advances in control design methods for robotic multi-agent systems (MAS), focussing on learning-based methods with safety considerations. We start by reviewing various notions of safety and liveness properties, and modeling frameworks used for problem formulation of MAS. Then we provide a comprehensive review of learning-based methods for safe control design for multi-robot systems. We start with various types of shielding-based methods, such as safety certificates, predictive filters, and reachability tools. Then, we review the current state of control barrier certificate learning in both a centralized and distributed manner, followed by a comprehensive review of multi-agent reinforcement learning with a particular focus on safety. Next, we discuss the state-of-the-art verification tools for the correctness of learning-based methods. Based on the capabilities and the limitations of the state of the art methods in learning and verification for MAS, we identify various broad themes for open challenges: how to design methods that can achieve good performance along with safety guarantees; how to decompose single-agent based centralized methods for MAS; how to account for communication-related practical issues; and how to assess transfer of theoretical guarantees to practice.
- ICRA 2024
 How to train your neural control barrier function: Learning safety filters for complex input-constrained systemsOswin So, Zachary Serlin, Makai Mann, Jake Gonzales, Kwesi Rutledge, Nicholas Roy, and Chuchu FanIn 2024 International Conference on Robotics and Automation (ICRA), 2024
How to train your neural control barrier function: Learning safety filters for complex input-constrained systemsOswin So, Zachary Serlin, Makai Mann, Jake Gonzales, Kwesi Rutledge, Nicholas Roy, and Chuchu FanIn 2024 International Conference on Robotics and Automation (ICRA), 2024Control barrier functions (CBF) have become popular as a safety filter to guarantee the safety of nonlinear dynamical systems for arbitrary inputs. However, it is difficult to construct functions that satisfy the CBF constraints for high relative degree systems with input constraints. To address these challenges, recent work has explored learning CBFs using neural networks via neural CBF (NCBF). However, such methods face difficulties when scaling to higher dimensional systems under input constraints. In this work, we first identify challenges that NCBFs face during training. Next, to address these challenges, we propose policy neural CBF (PNCBF), a method of constructing CBFs by learning the value function of a nominal policy, and show that the value function of the maximum-over-time cost is a CBF. We demonstrate the effectiveness of our method in simulation on a variety of systems ranging from toy linear systems to an F-16 jet with a 16-dimensional state space. Finally, we validate our approach on a two-agent quadcopter system on hardware under tight input constraints.



2023
- RSS 2023
 Solving Stabilize-Avoid Optimal Control via Epigraph Form and Deep Reinforcement LearningOswin So and Chuchu FanIn Robotics: Science and Systems (RSS), 2023
Solving Stabilize-Avoid Optimal Control via Epigraph Form and Deep Reinforcement LearningOswin So and Chuchu FanIn Robotics: Science and Systems (RSS), 2023Tasks for autonomous robotic systems commonly require stabilization to a desired region while maintaining safety specifications. However, solving this multi-objective problem is challenging when the dynamics are nonlinear and high-dimensional, as traditional methods do not scale well and are often limited to specific problem structures. To address this issue, we propose a novel approach to solve the stabilize-avoid problem via the solution of an infinite-horizon constrained optimal control problem (OCP). We transform the constrained OCP into epigraph form and obtain a two-stage optimization problem that optimizes over the policy in the inner problem and over an auxiliary variable in the outer problem. We then propose a new method for this formulation that combines an on-policy deep reinforcement learning algorithm with neural network regression. Our method yields better stability during training, avoids instabilities caused by saddle-point finding, and is not restricted to specific requirements on the problem structure compared to more traditional methods. We validate our approach on different benchmark tasks, ranging from low-dimensional toy examples to an F16 fighter jet with a 17-dimensional state space. Simulation results show that our approach consistently yields controllers that match or exceed the safety of existing methods while providing ten-fold increases in stability performance from larger regions of attraction.
- ICRA 2023MPOGames: Efficient Multimodal Partially Observable Dynamic GamesOswin So, Paul Drews, Thomas Balch, Velin Dimitrov, Guy Rosman, and Evangelos A. TheodorouIn 2023 IEEE International Conference on Robotics and Automation (ICRA), 2023
Game theoretic methods have become popular for planning and prediction in situations involving rich multi-agent interactions. However, these methods often assume the existence of a single local Nash equilibria and are hence unable to handle uncertainty in the intentions of different agents. While maximum entropy (MaxEnt) dynamic games try to address this issue, practical approaches solve for MaxEnt Nash equilibria using linear-quadratic approximations which are restricted to unimodal responses and unsuitable for scenarios with multiple local Nash equilibria. By reformulating the problem as a POMDP, we propose MPOGames, a method for efficiently solving MaxEnt dynamic games that captures the interactions between local Nash equilibria. We show the importance of uncertainty-aware game theoretic methods via a two-agent merge case study. Finally, we prove the real-time capabilities of our approach with hardware experiments on a 1/10th scale car platform.

2022
- ML4PS 2022Data-driven discovery of non-Newtonian astronomy via learning non-Euclidean HamiltonianOswin So, Gongjie Li, Evangelos A Theodorou, and Molei TaoIn Machine Learning and the Physical Sciences Workshop NeurIPS, 2022
Incorporating the Hamiltonian structure of physical dynamics into deep learning models provides a powerful way to improve the interpretability and prediction accuracy. While previous works are mostly limited to the Euclidean spaces, their extension to the Lie group manifold is needed when rotations form a key component of the dynamics, such as the higher-order physics beyond simple point-mass dynamics for N-body celestial interactions. Moreover, the multiscale nature of these processes presents a challenge to existing methods as a long time horizon is required. By leveraging a symplectic Lie-group manifold preserving integrator, we present a method for data-driven discovery of non-Newtonian astronomy. Preliminary results show the importance of both these properties in training stability and prediction accuracy.
- NeurIPS 2022Deep Generalized Schrodinger BridgeGuan-Horng Liu, Tianrong Chen*, Oswin So*, and Evangelos A TheodorouIn Thirty-Sixth Conference on Neural Information Processing Systems (NeurIPS), 2022
Mean-Field Game (MFG) serves as a crucial mathematical framework in modeling the collective behavior of individual agents interacting stochastically with a large population. In this work, we aim at solving a challenging class of MFGs in which the differentiability of these interacting preferences may not be available to the solver, and the population is urged to converge exactly to some desired distribution. These setups are, despite being well-motivated for practical purposes, complicated enough to paralyze most (deep) numerical solvers. Nevertheless, we show that Schrödinger Bridge - as an entropy-regularized optimal transport model - can be generalized to accepting mean-field structures, hence solving these MFGs. This is achieved via the application of Forward-Backward Stochastic Differential Equations theory, which, intriguingly, leads to a computational framework with a similar structure to Temporal Difference learning. As such, it opens up novel algorithmic connections to Deep Reinforcement Learning that we leverage to facilitate practical training. We show that our proposed objective function provides necessary and sufficient conditions to the mean-field problem. Our method, named Deep Generalized Schrödinger Bridge (DeepGSB), not only outperforms prior methods in solving classical population navigation MFGs, but is also capable of solving 1000-dimensional opinion depolarization, setting a new state-of-the-art numerical solver for high-dimensional MFGs. Our code will be made available at https://github.com/ghliu/DeepGSB.
- Multimodal Maximum Entropy Dynamic GamesOswin So, Kyle Stachowicz, and Evangelos A. TheodorouarXiv preprint (in submission), 2022
Environments with multi-agent interactions often result a rich set of modalities of behavior between agents due to the inherent suboptimality of decision making processes when agents settle for satisfactory decisions. However, existing algorithms for solving these dynamic games are strictly unimodal and fail to capture the intricate multimodal behaviors of the agents. In this paper, we propose MMELQGames (Multimodal Maximum-Entropy Linear Quadratic Games), a novel constrained multimodal maximum entropy formulation of the Differential Dynamic Programming algorithm for solving generalized Nash equilibria. By formulating the problem as a certain dynamic game with incomplete and asymmetric information where agents are uncertain about the cost and dynamics of the game itself, the proposed method is able to reason about multiple local generalized Nash equilibria, enforce constraints with the Augmented Lagrangian framework and also perform Bayesian inference on the latent mode from past observations. We assess the efficacy of the proposed algorithm on two illustrative examples: multi-agent collision avoidance and autonomous racing. In particular, we show that only MMELQGames is able to effectively block a rear vehicle when given a speed disadvantage and the rear vehicle can overtake from multiple positions.
- RSS 2022Decentralized Safe Multi-agent Stochastic Optimal Control using Deep FBSDEs and ADMMMarcus A. Pereira, Augustinos D. Saravanos, Oswin So, and Evangelos A. TheodorouIn Robotics: Science and Systems (RSS), 2022
In this work, we propose a novel safe and scalable decentralized solution for multi-agent control in the presence of stochastic disturbances. Safety is mathematically encoded using stochastic control barrier functions and safe controls are computed by solving quadratic programs. Decentralization is achieved by augmenting to each agent’s optimization variables, copy variables, for its neighboring agents. This allows us to decouple the centralized multi-agent optimization problem. How- ever, to ensure safety, neighboring agents must agree on what is safe for both of us and this creates a need for consensus. To enable safe consensus solutions, we incorporate an ADMM- based approach. Specifically, we propose a Merged CADMM- OSQP implicit neural network layer, that solves a mini-batch of both, local quadratic programs as well as the overall con- sensus problem, as a single optimization problem. This layer is embedded within a Deep FBSDEs network architecture at every time step, to facilitate end-to-end differentiable, safe and decentralized stochastic optimal control. The efficacy of the proposed approach is demonstrated on several challenging multi- robot tasks in simulation. By imposing requirements on safety specified by collision avoidance constraints, the safe operation of all agents is ensured during the entire training process. We also demonstrate superior scalability in terms of computational and memory savings as compared to a centralized approach.
2021
- ICRA 2022Maximum Entropy Differential Dynamic ProgrammingOswin So, Ziyi Wang, and Evangelos A. TheodorouIn 2022 International Conference on Robotics and Automation (ICRA), 2021
In this paper, we present a novel maximum entropy formulation of the Differential Dynamic Programming algorithm and derive two variants using unimodal and multimodal value functions parameterizations. By combining the maximum entropy Bellman equations with a particular approximation of the cost function, we are able to obtain a new formulation of Differential Dynamic Programming which is able to escape from local minima via exploration with a multimodal policy. To demonstrate the efficacy of the proposed algorithm, we provide experimental results using four systems on tasks that are represented by cost functions with multiple local minima and compare them against vanilla Differential Dynamic Programming. Furthermore, we discuss connections with previous work on the linearly solvable stochastic control framework and its extensions in relation to compositionality.
- RSS 2021Variational Inference MPC using Tsallis DivergenceZiyi Wang*, Oswin So*, Jason Gibson, Bogdan Vlahov, Manan S Gandhi, Guan-Horng Liu, and Evangelos A TheodorouIn Robotics: Science and Systems (RSS), 2021
In this paper, we provide a generalized framework for Variational Inference-Stochastic Optimal Control by using thenon-extensive Tsallis divergence. By incorporating the deformed exponential function into the optimality likelihood function, a novel Tsallis Variational Inference-Model Predictive Control algorithm is derived, which includes prior works such as Variational Inference-Model Predictive Control, Model Predictive PathIntegral Control, Cross Entropy Method, and Stein VariationalInference Model Predictive Control as special cases. The proposed algorithm allows for effective control of the cost/reward transform and is characterized by superior performance in terms of mean and variance reduction of the associated cost. The aforementioned features are supported by a theoretical and numerical analysis on the level of risk sensitivity of the proposed algorithm as well as simulation experiments on 5 different robotic systems with 3 different policy parameterizations.
- Spatio-Temporal Differential Dynamic Programming for Control of FieldsEthan N Evans, Oswin So, Andrew P Kendall, Guan-Horng Liu, and Evangelos A TheodorouarXiv preprint (in submission), 2021
We consider the optimal control problem of a general nonlinear spatio-temporal system described by Partial Differential Equations (PDEs). Theory and algorithms for control of spatio-temporal systems are of rising interest among the automatic control community and exhibit numerous challenging characteristic from a control standpoint. Recent methods focus on finite-dimensional optimization techniques of a discretized finite dimensional ODE approximation of the infinite dimensional PDE system. In this paper, we derive a differential dynamic programming (DDP) framework for distributed and boundary control of spatio-temporal systems in infinite dimensions that is shown to generalize both the spatio-temporal LQR solution, and modern finite dimensional DDP frameworks. We analyze the convergence behavior and provide a proof of global convergence for the resulting system of continuous-time forward-backward equations. We explore and develop numerical approaches to handle sensitivities that arise during implementation, and apply the resulting STDDP algorithm to a linear and nonlinear spatio-temporal PDE system. Our framework is derived in infinite dimensional Hilbert spaces, and represents a discretization-agnostic framework for control of nonlinear spatio-temporal PDE systems.
- L4DC 2021Adaptive Risk Sensitive Model Predictive Control with Stochastic SearchZiyi Wang, Oswin So, Keuntaek Lee, and Evangelos A. TheodorouIn Learning for Dynamics & Control Conference, 2021
We present a general framework for optimizing the Conditional Value-at-Risk for dynamical systems using stochastic search. The framework is capable of handling the uncertainty from the initial condition, stochastic dynamics, and uncertain parameters in the model. The algorithm is compared against a risk-sensitive distributional reinforcement learning framework and demonstrates outperformance on a pendulum and cartpole with stochastic dynamics. We also showcase the applicability of the framework to robotics as an adaptive risk-sensitive controller by optimizing with respect to the fully nonlinear belief provided by a particle filter on a pendulum, cartpole, and quadcopter in simulation.
- In Submission
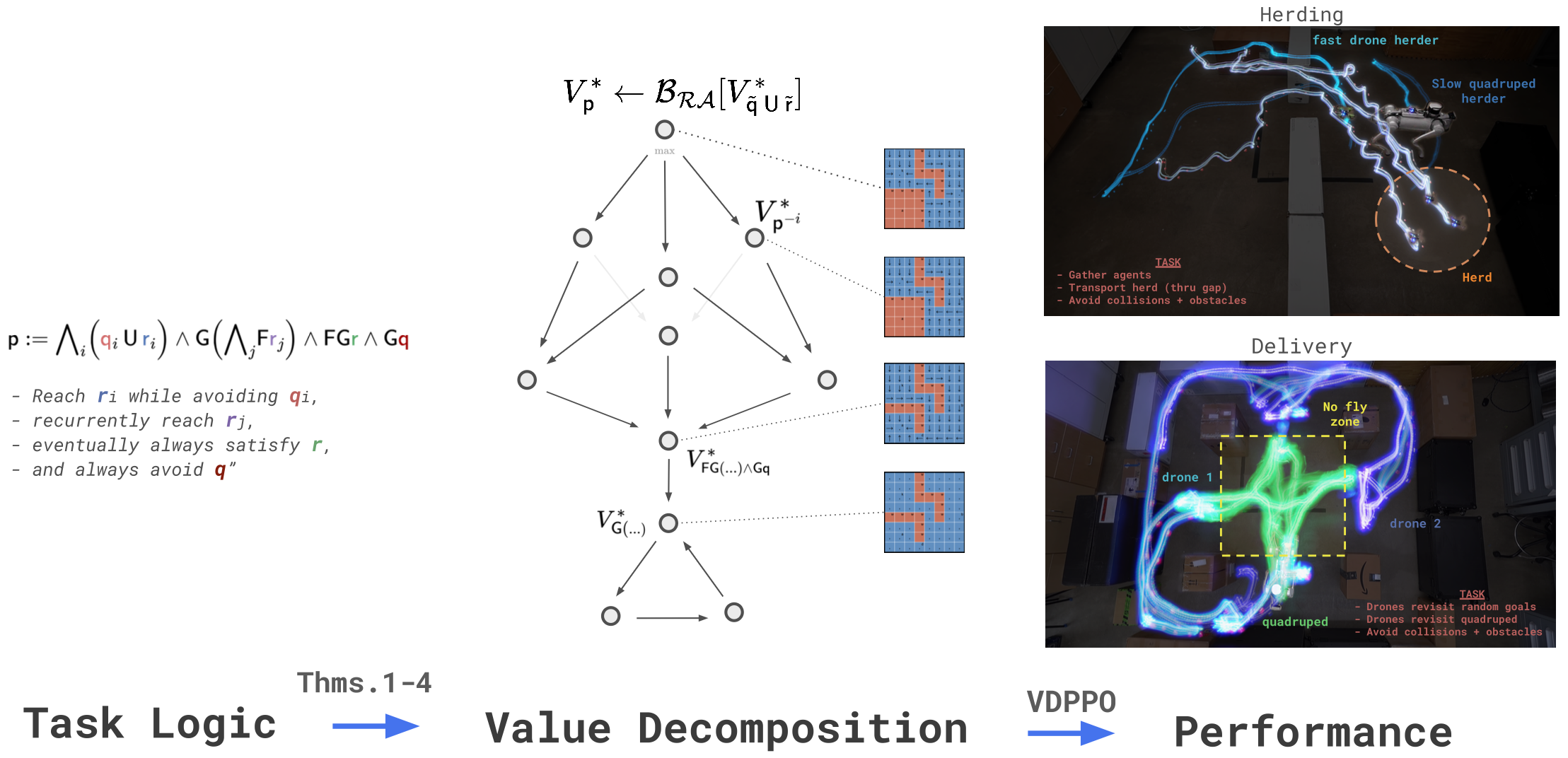 Bellman Value Decomposition for Task Logic in Safe Optimal ControlWilliam Sharpless*, Oswin So*, Dylan Hirsch, Sylvia Herbert, and Chuchu FanIn Submission
Bellman Value Decomposition for Task Logic in Safe Optimal ControlWilliam Sharpless*, Oswin So*, Dylan Hirsch, Sylvia Herbert, and Chuchu FanIn SubmissionReal-world tasks involve nuanced combinations of goal and safety specifications, which often directly compete. In high dimensions, the challenge is exacerbated: formal automata become cumbersome, and the combination of sparse rewards tends to require laborious tuning. In this work, we consider the structure of the Bellman Value as a means to naturally organize the problem for improved automatic performance without introducing additional abstractions. Namely, we prove the Bellman Value for a complex task defined in temporal logic can be decomposed into a graph of Bellman Values, where the graph is connected by a set of well-studied Bellman equations (BEs): the Reach-Avoid BE, the Avoid BE, and a novel type, the Reach-Avoid-Loop BE. From this perspective, we design a specialized PPO variant, Value-Decomposition PPO (VDPPO) that uses a single learned representation by embedding the decomposed Value graph. We conduct a variety of simulated and real multi-objective experiments, including delivery and herding, to test our method on diverse high-dimensional systems involving heterogeneous teams and complex agents. Ultimately, we find this approach greatly improves performance over existing baselines, balancing safety and liveness automatically.
