Overview
- Feasibility-Guided Exploration (FGE) is a framework for solving safety problems over a set of parameters (dictating the initial state, safe set, and dynamics), even when the set of parameters may include parameters that are infeasible (i.e. always unsafe).
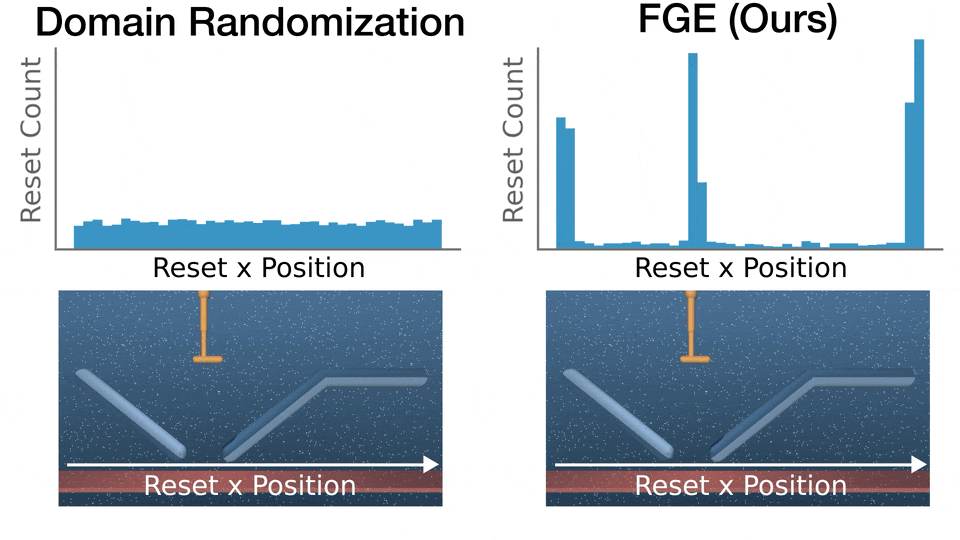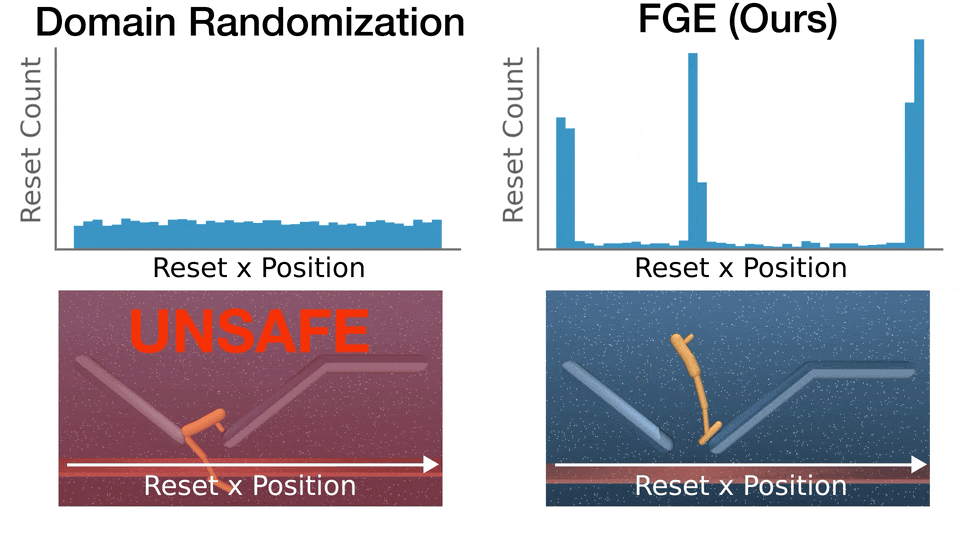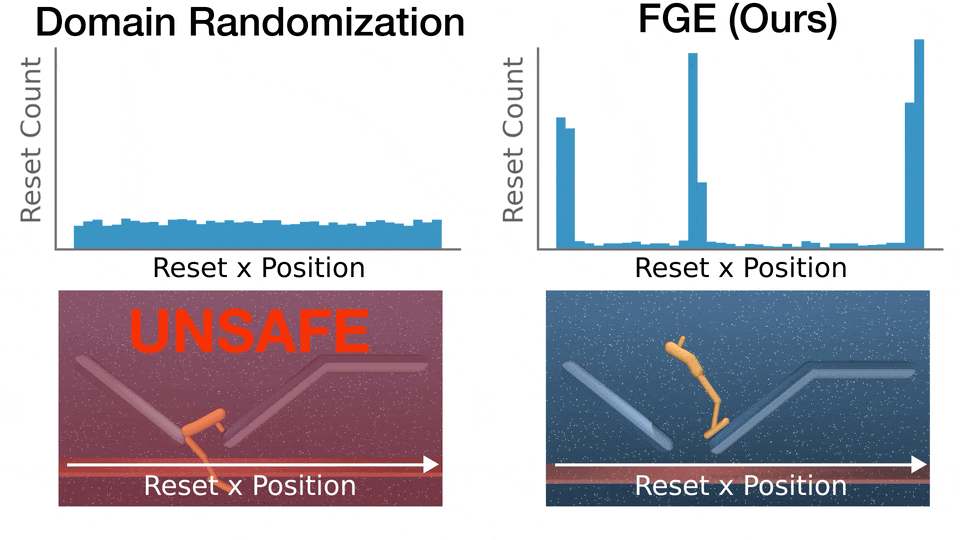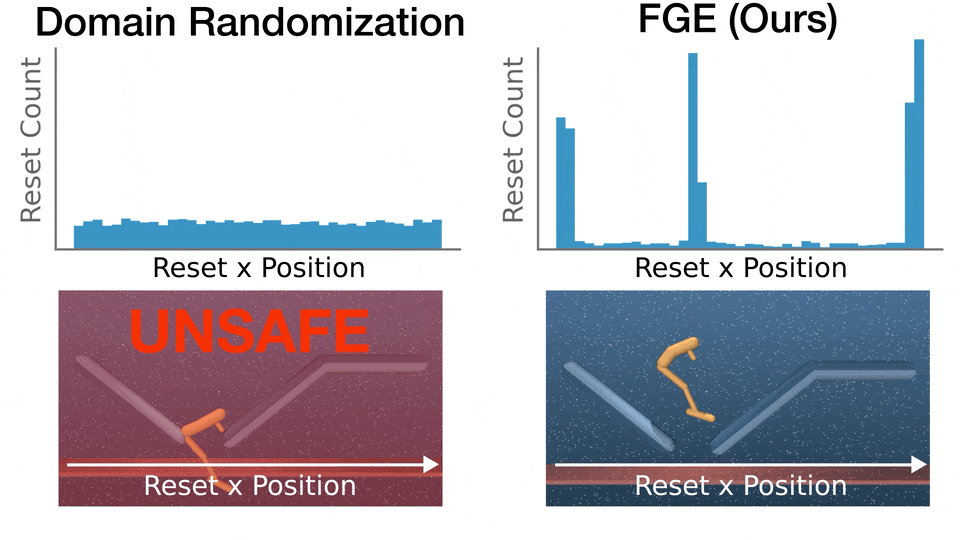
- FGE is performant, with many hard parameters that only FGE is able to render safe (high Coverage Gain), while FGE doesn't regress performance on easier parameters (low Coverage Loss).
Results


Challenges of Robust Safety
We tackle the problem of solving for a policy that can maintain safety over a set of parameters \( \Theta \), where the parameters dictates the initial state, safe set and dynamics:
Note that, instead of "for all \(\theta \in \Theta\)" as in typical robust optimization, we use "as many \(\theta\) as possible" because we do not assume that the entire set of \(\Theta\) is feasible.
To see why this is a problem, consider a toy static example where the state \( \mathbf{s}_0 = 0 \) always starts at zero, the next state is determined by the action \( \mathbf{s}_1 = a_0 \in [0, 1] \), and the parameter \(\theta \in [-1,1]\) specifies the failure set \(\mathcal{F}_\theta = \{ \mathbf{s} \mid \mathbf{s} < \theta \} \).
For \(\theta < 0\), there are no actions that can keep the system safe. In particular, if we examine the robust optimization problem:
Any choice of \(a_0\) is equally bad, so a robust optimization approach (such as RARL [1] ) could choose \(a_0 = 1\) which is only safe for \(\theta = 1\), even though \(a_0 = 0\) is safe for a larger set of parameters \(\theta \geq 0\).
Parameter-Robust Avoid Problem with Unknown Feasibility
We thus solve the following optimization problem instead, which maximizes the size of the safe set:
where 1 can be written as the following robust optimization problem:
There are two immediate challenges:
- Given an estimate, how do we solve the robust optimization problem?
- How do we identify the largest set of feasible parameters \( \bar{\Theta} \)?
Feasibility-Guided Exploration (FGE)

Abstract
Recent advances in deep reinforcement learning (RL) have achieved strong results on high-dimensional control tasks, but applying RL to optimal safe controller synthesis raises a fundamental mismatch: optimal safe controller synthesis seeks to maximize the set of states from which a system remains safe indefinitely, while RL optimizes expected returns over a user-specified distribution. This mismatch can yield policies that perform poorly on low-probability states still within the safe set. A natural alternative is to frame the problem as a robust optimization over a set of initial conditions that specify the initial state, dynamics and safe set, but whether this problem has a solution depends on the feasibility of the specified set, which is unknown a priori. We propose Feasibility-Guided Exploration (FGE), a method that simultaneously identifies a subset of feasible initial conditions under which a safe policy exists, and learns a policy to solve the optimal control problem over this set of initial conditions. Empirical results demonstrate that FGE learns policies with over 50% more coverage than the best existing method for challenging initial conditions across tasks in the MuJoCo simulator.
References
- 1. Lerrel Pinto, James Davidson, Rahul Sukthankar, and Abhinav Gupta, "Robust Adversarial Reinforcement Learning", Proceedings of the 34th International Conference on Machine Learning (ICML) , 2017